
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- classification
- CES 2O21 참가
- pycharm
- 대이터
- 결합전문기관
- 재귀함수
- 데이터전문기관
- mglearn
- discrete_scatter
- web 개발
- postorder
- Keras
- KNeighborsClassifier
- html
- inorder
- 머신러닝
- vscode
- web 용어
- C언어
- paragraph
- broscoding
- 웹 용어
- 자료구조
- java역사
- cudnn
- web 사진
- bccard
- web
- CES 2O21 참여
- tensorflow
Archives
- Today
- Total
bro's coding
keras.classifier.cifar10 본문
반응형
The CIFAR-10 dataset (Canadian Institute For Advanced Research) is a collection of images that are commonly used to train machine learning and computer vision algorithms. It is one of the most widely used datasets for machine learning research.[1][2] The CIFAR-10 dataset contains 60,000 32x32 color images in 10 different classes.[3] The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks. There are 6,000 images of each class.
(https://en.wikipedia.org/wiki/CIFAR-10)
from __future__ import absolute_import, division, print_function, unicode_literals
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_imaages / 255.0
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 4, 4, 64) 36928
_________________________________________________________________
flatten_1 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 65600
_________________________________________________________________
dense_3 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
N : number of image's pixel(이미지의 픽셀 수)
S : stride(필터 이동 간격)
F : filter size(필터 크기 3X3)
convolution [ (N-F)/S+1 ]
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))Train on 50000 samples, validate on 10000 samples
Epoch 1/10
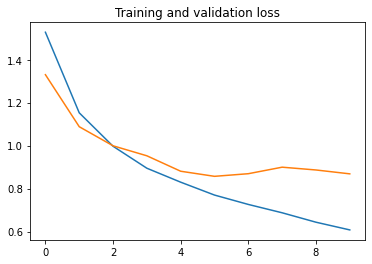
50000/50000 [==============================] - 79s 2ms/step - loss: 1.5278 - acc: 0.4412 - val_loss: 1.3302 - val_acc: 0.5279
Epoch 2/10
50000/50000 [==============================] - 78s 2ms/step - loss: 1.1527 - acc: 0.5915 - val_loss: 1.0880 - val_acc: 0.6099
Epoch 3/10
50000/50000 [==============================] - 75s 2ms/step - loss: 0.9970 - acc: 0.6507 - val_loss: 0.9991 - val_acc: 0.6487
Epoch 4/10
50000/50000 [==============================] - 78s 2ms/step - loss: 0.8947 - acc: 0.6863 - val_loss: 0.9526 - val_acc: 0.6654
Epoch 5/10
50000/50000 [==============================] - 78s 2ms/step - loss: 0.8297 - acc: 0.7093 - val_loss: 0.8807 - val_acc: 0.6954
Epoch 6/10
50000/50000 [==============================] - 75s 2ms/step - loss: 0.7698 - acc: 0.7291 - val_loss: 0.8570 - val_acc: 0.6988
Epoch 7/10
50000/50000 [==============================] - 75s 2ms/step - loss: 0.7261 - acc: 0.7460 - val_loss: 0.8692 - val_acc: 0.6973
Epoch 8/10
50000/50000 [==============================] - 77s 2ms/step - loss: 0.6873 - acc: 0.7596 - val_loss: 0.8995 - val_acc: 0.6901
Epoch 9/10
50000/50000 [==============================] - 77s 2ms/step - loss: 0.6434 - acc: 0.7736 - val_loss: 0.8866 - val_acc: 0.7021
Epoch 10/10
50000/50000 [==============================] - 75s 2ms/step - loss: 0.6075 - acc: 0.7851 - val_loss: 0.8685 - val_acc: 0.7122
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print(test_loss,test_acc)
# Retrieve a list of accuracy results on training and validation data
# sets for each training epoch
acc = history.history['acc']
val_acc = history.history['val_acc']
# Retrieve a list of list results on training and validation data
# sets for each training epoch
loss = history.history['loss']
val_loss = history.history['val_loss']
# Get number of epochs
epochs = range(len(acc))
# Plot training and validation accuracy per epoch
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
plt.title('Training and validation accuracy')
plt.figure()
# Plot training and validation loss per epoch
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')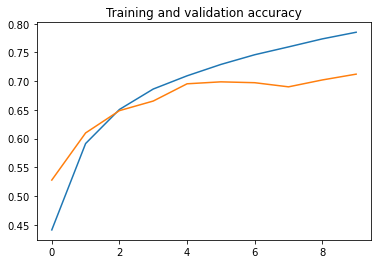
반응형
'[AI] > python.keras' 카테고리의 다른 글
| keras.workflow (0) | 2020.08.10 |
|---|---|
| 머신러닝 용어집 (1) | 2020.06.09 |
| distinguish dog and cat (0) | 2020.06.09 |
| keras.layers.Dropout (0) | 2020.05.13 |
| keras.layers.Flatten (0) | 2020.05.13 |
| keras.save (0) | 2020.05.13 |
| keras.score (0) | 2020.05.13 |
| keras.mnist(중간층) (0) | 2020.05.13 |
'[AI]/python.keras' Related Articles
more

Comments