
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- web
- bccard
- web 사진
- pycharm
- Keras
- 대이터
- vscode
- inorder
- java역사
- CES 2O21 참여
- postorder
- C언어
- 재귀함수
- cudnn
- 결합전문기관
- paragraph
- web 용어
- mglearn
- broscoding
- 자료구조
- 웹 용어
- discrete_scatter
- web 개발
- tensorflow
- classification
- 데이터전문기관
- html
- KNeighborsClassifier
- 머신러닝
- CES 2O21 참가
Archives
- Today
- Total
bro's coding
sklearn.feature_extraction.text.CountVectorizer.max_df변화 관찰 본문
[AI]/python.sklearn
sklearn.feature_extraction.text.CountVectorizer.max_df변화 관찰
givemebro 2020. 4. 28. 10:25반응형
불용어 적용(stop words)
관사 지시 대명사 등등 관용적으로 사용하는 단어들 where when the it etc...
max_df(너무 많이 나오는 애들)(비율)
stop_words : 불용어 목록을 지정함
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB
num_of_words=[]
scores_BernoulliNB=[]
max_df=np.arange(0.1,1,0.1)
for df in max_df:
vect=CountVectorizer(max_df=df)
vect.fit(text_train)
num_of_words.append(len(vect.get_feature_names()))
X_train=vect.transform(text_train)
X_test=vect.transform(text_test)
model=BernoulliNB()
model.fit(X_train,y_train)
scores_BernoulliNB.append(model.score(X_test,y_test))
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
plt.plot(num_of_words,'b:o')
plt.xticks(min_df)
plt.subplot(1,2,2)
plt.plot(scores_BernoulliNB,'b:o')
plt.yticks(rotation=-50)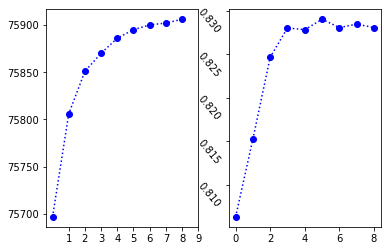
반응형
'[AI] > python.sklearn' 카테고리의 다른 글
| sklearn.feature_extraction.text.CountVectorizer.ngram_range적용 (0) | 2020.04.28 |
|---|---|
| sklearn.feature_extraction.text.TfidfTransformer.LogisticRegression적용 (0) | 2020.04.28 |
| sklearn.feature_extraction.text.TfidfTransformer (0) | 2020.04.28 |
| sklearn.feature_extraction.text.CountVectorizer.stop_words적용 (0) | 2020.04.28 |
| sklearn.feature_extraction.text.CountVectorizer.min_df변화 관찰 (1) | 2020.04.28 |
| sklearn.textdata.BernoulliNB적용 (0) | 2020.04.28 |
| sklearn.textdata.LogisticRegression적용 (0) | 2020.04.27 |
| sklearn.textdata.단어집과 문장 대조하기 (0) | 2020.04.27 |
'[AI]/python.sklearn' Related Articles
more

Comments